
The high concurrency of the database has been a problem perplexing the database personnel. How to solve the problem of high concurrency of the database?
The following methods can deal with concurrent operations of large amounts of data.
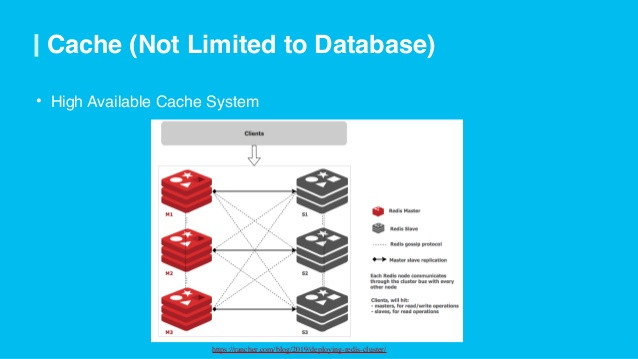
1. Use Cache
Use the program to save it into memory. Use a caching framework. Save it with a specific type value to distinguish empty data from not cached states.
2. Database Optimization
There are table structure optimization and SQL statement optimization. There are syntax optimization and processing logic optimization. You can use stored procedures.
3. Separation of Active Data
It can be divided into active users and inactive users.
4. Batch Read and Delayed Modification
High concurrency can merge multiple query requests into one. Highly concurrent and frequently modified can be stored in the cache.
5. Separation of Read and Write
Multiple database servers are configured. Configure master-slave databases. The master database is used for writing. The slave database is used for reading.
6. Distributed Database
Store different tables in different databases. Put them in different servers.
To ensure the consistency and integrity of the database, many table associations are designed. For example, we can store the region in a separate region table. If the data redundancy is low, the integrity of the data can be guaranteed. In this way, the data throughput speed is improved. The integrity of the data is ensured. Do not associate a self-increasing property field with a child table as a primary key. This is not convenient for system migration and data recovery.
You need to pay attention to the specific issues in the design of tables.
1. The length of data rows should not exceed bytes. If this length is exceeded, the data in the physical page will occupy two rows. It will cause storage fragmentation and reducing query efficiency.
2. You can choose the number type with the number type field. String-type fields reduce query and join performance and increase storage overhead. The engine is processing queries and concatenating each character in the comparison string one by one. For the digital type, only one comparison is enough.
3. Both the immutable character type char and the variable character type VARCHAR are bytes. Char queries are fast but consume storage space. VARCHAR queries are slow, but save more storage space. You can choose flexibly when designing fields. For example, CHAR can be selected for fields with little change in length, such as user name and password. VARCHAR can be selected for fields with equal comment change size.
4. The length of the field should short. This can improve the efficiency of the query. While establishing indexes, it can reduce the consumption of resources.
The above are the detailed steps and methods to solve the high concurrency of the database. I hope these methods can help you.






